
Opened 10 months ago
Last modified 9 months ago
#192 new defect
Possible evidence of memory leaks (XIOS3)
| Reported by: | acc | Owned by: | ymipsl |
|---|---|---|---|
| Priority: | major | Component: | XIOS |
| Version: | trunk | Keywords: | |
| Cc: |
Description
XIOS3-trunk is still a work in progress so the purpose of this ticket is not to complain about possible memory leaks but rather to present some evidence of current behaviour that may aid in detection.
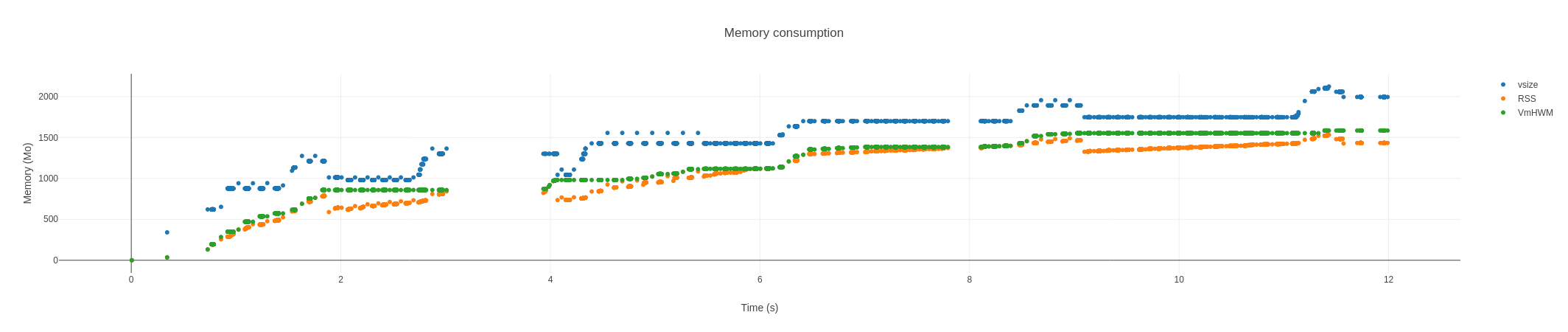
A eORCA025 configuration has been run on two clusters: an intel ice-lake cluster using ifort and intel-MPI and an AMD cluster using Cray compilers, Cray-MPICH and UCX protocols. The intel test successfully completes a year of integration with 1019 ocean cores and 52 xios3 servers. Full 5day, monthly and annual mean files are produced. The Cray test crashes out in month 7 with a probable OOM error. In both cases, monitoring the total memory used per node shows a persistent growth throughout the run. 5 day and monthly means are split at monthly intervals so usage should plateau after a few months. A clear cycle of monthly events is evident but usage never levels off. Some nodes on the intel cluster appear to free memory in the third quarter. Unfortunately, the Cray test reaches its limits before that point.
Graphs are attached:
Attachments (9)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (20)
Changed 10 months ago by acc
comment:1 Changed 10 months ago by acc
")
")
comment:2 Changed 10 months ago by jderouillat
Can you confirm that you are using the p2p protocol ?
With the HEAD commenting the #include "mpi.hpp" ?
We monitored the memory consumption on the legacy protocol (especially on NEMO), but this is something we didn't do yet on alternative protocols, which own their data structure. This is a good time to do so, I'll do somthing based on the generic_testcase.
comment:3 Changed 10 months ago by acc
Yes, p2p transport_protocol
Not quite the head: 2566 with Changesets 2577 and 2579 added. Still didn't finish cleanly for me with the HEAD last time I tried. Will try again.
comment:4 Changed 10 months ago by jderouillat
I confirm that the p2p protocol is not clean regarding memory consumption on servers.
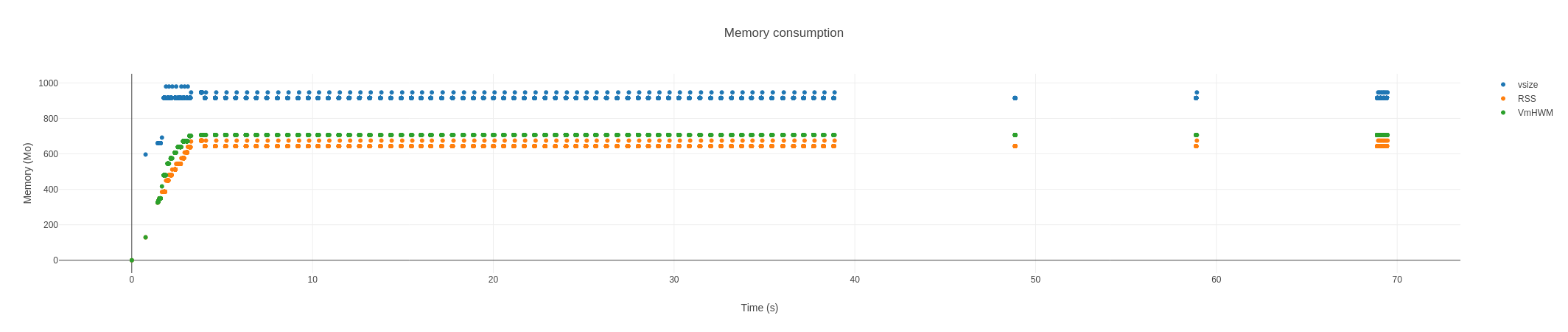
In attachment, for a given experiment with 256 clients x 10 servers (8 N1 + 2 N2), 4000 timesteps, write every 50 timesteps of instant of a 3D field (576 x 672 x 75), the memory consumption of the first N1 server (a gatherer, no IO) for the legacy and the p2p protocols.
On the client side, an overhead (20%) appears on p2p regarding legacy. This overhead is stable along the time.
Changed 10 months ago by jderouillat
Changed 10 months ago by jderouillat
Changed 10 months ago by jderouillat
comment:5 Changed 10 months ago by jderouillat
To be exhaustive, the consumption of the one_sided protocol in the same context has been added :



comment:6 Changed 10 months ago by acc
Another pair of tests (with p2p); as before but with no actual file output. The Anemone (intel) example suggests there is a small leak on the client side too but very much less than with active servers. The Archer2 (Cray-AMD) example probably illustrates a suspected issue with the Cray's implementation of UCX (see: Archer2 known issues) in addition to the leaks present in the Intel case.


comment:7 Changed 9 months ago by jderouillat
Some typo have been fixed in 2585, it concerns :
- the size of the buffer which were oversized on clients and so servers
- a growing factor applied on the server side regularly
Moreover, we identified that the p2p protocol could be greedy regarding the memory consumption for now, receiving requests on servers from clients are completely prioritized regarding to their processing without limits on the memory consumption.
So, if clients are so fast that they can sent requests too frequently regarding to the servers capacities, buffers will accumulate on servers.
In the short term, we will be looking to set a mechanism to moderate this ratio requests received / request computed regarding the memory consumption.
That said, it could be interesting to reproduce your figures with the XIOS3 head to distinguish the effect of typos and of the algorithm (bug reported in Issue 191 should be fixed too).
comment:8 Changed 9 months ago by acc
Yes much better. Our Intel, ice-lake cluster (Anemone) has a much flatter utilisation:

A near-equivalent on the AMD, ARCHER2 cluster is also improved:

For the latter, all xios_servers have been isolated on the first 4 nodes (13 per node). I guess the spike at the end is from the node with the writer services for the annual means? Again the more linear growth on the ocean nodes is probably down to underlying issues on this machine.
comment:9 Changed 9 months ago by jderouillat
As announced in a previous message, we implement in the p2p protocol (in 2594) a control of the memory used by servers.
It has been validated on our coupled model using some gatherers and a writer.
It seems that you are not concerned but a warning : a problem has been identified finalizing the simulation when data are read by the servers and prefetched on clients but not treated. An exception Try to delete buffer that is not empty could be raised.
comment:10 Changed 9 months ago by acc
I'm not seeing this particular error but I am having issues at the end of runs with this error:
Abort(17) on node 73 (rank 73 in comm 0): Fatal error in PMPI_Testall: See the MPI_ERROR field in MPI_Status for the error code
and the job crashes before completing the final set of 1d, 5d and 1m means (which have been successfully written for the simulated year up to this point with appropriate split_freqs) and the 1y means (which are only written at the end of the year). Rank 73 is one of the 90 xios servers in play. The 1326 nemo processes have finished cleanly and completed all their restart files.
Is this possibly a manifestation of the same issue? I'll try again after I've updated from 2593 to 2594.
comment:11 Changed 9 months ago by acc
...the answer appears to be yes. A retry with 2594 has successfully completed a simulated year and produced all the output at the end. :)
memory use per node on Anemone (Intel cluster)