| Version 6 (modified by cdlod, 14 years ago) (diff) |
|---|
Tangent and adjoint models (TAM)
TAM what for ?
The development of tangent and adjoint models is an important step in addressing sensitivity analysis and variational data assimilation problems in Oceanography. Sensitivity analysis is the study of how model output varies with changes in model inputs. The sensitivity information given by the adjoint model is used directly to gain an understanding of the physical processes. In data assimilation, one considers a cost function which is a measure of the model-data misfit. The adjoint sensitivities are used to build the gradient for descent algorithms. Similarly the tangent model is used in the context of the incremental algorithms to linearize the cost function around a background control.
Tangent and Adjoint coding principle
the original program P, whatever its size and run time, computes a function F, X∈ IRm → Y ∈ IRn which is the composition of the elementary functions computed by each run-time instruction. In other words if P executes a sequence of elementary statements Ik,k ∈ [1..p], then P actually evaluates
F = fp ◦ fp−1 ◦···◦ f1 ,
where each fk is the function implemented by Ik. Therefore one can apply the chain rule of derivative calculus to get the Jacobian matrix F!′, i.e. the partial derivatives of each component of Y with respect to each component of X. Calling X0 = X and Xk = fk(Xk−1) the successive values of all intermediate variables, i.e. the successive states of the memory throughout execution of P, we get
F′(X) = f′p(Xp−1) × f′p − 1(Xp−2)×···×f′1(X0) . (1)
The derivatives f′k of each elementary instruction are easily built, and must be inserted in the differentiated program so that each of them has the values Xk−1 directly available for use. This process yields analytic derivatives, that are exact up to numerical accuracy. In practice, two sorts of derivatives are of particular importance in scientific computing: the tangent (or directional) derivatives, and the adjoint (or reverse) derivatives. The tangent derivative is the product
dY = F′(X) × dX
of the full Jacobian times a direction dX in the input space. From equation (1), we find
dY = F′(X) × dX = f′p(Xp−1) × f′p−1(Xp−2)×···×f′1(X0)×dX (2)
which is most cheaply executed from right to left because matrix × vector products are much cheaper than matrix × matrix products. This is also the most convenient execution order because it uses the intermediate values Xk in the same order as the program P builds them. On the other hand the adjoint derivative is the product Xad = F′∗(X) × Yad of the transposed Jacobian times a weight vector Yad in the output space. The resulting Xad is the gradient of the dot product (Y · Yad ). From equation (1), we find
Xad =F′∗(X)×Yad =f′1∗(X0)×···×f′∗p-1(Xp-2)×f′*p(Xp-1)×Yad (3)
which is also most cheaply executed from right to left. However, this uses the intermediate values Xk in the inverse of their building order in P.
for specific details about practical adjoint coding refer to Giering and Kaminski (1998)
Potential issues
- the major approximations : non differentiability issues, simplification of the direct model before linearization, validity of the tangent linear hypothesis over some time window, etc.
- the validation interface : classical tests for checking the correctness of tangent and adjoint models
- numerical problems
- numerical cost issues
Attachments (5)
- ad_6.png (5.9 KB) - added by avidard 14 years ago.
- ad_5.png (11.1 KB) - added by avidard 14 years ago.
- ad_1.png (5.4 KB) - added by avidard 14 years ago.
- ad_3.png (7.3 KB) - added by avidard 14 years ago.
- ad_4.png (17.4 KB) - added by avidard 14 years ago.
{kind=link}
{kind=link}
{kind=link}
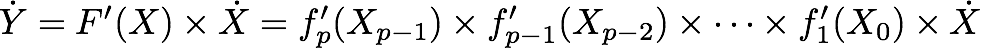{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
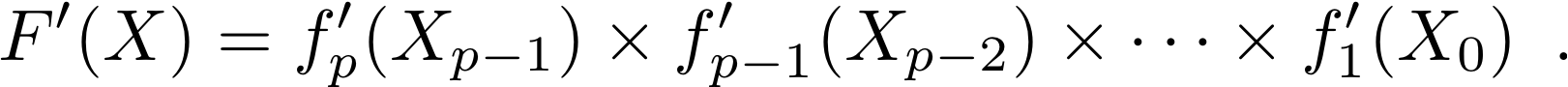{kind=link}
Download all attachments as: .zip