| Version 18 (modified by dsolyga, 11 years ago) (diff) |
|---|
Parallelism performances of ORCHIDEE
The performances of ORCHIDEE in parallel are very poor. Martial identified the problem with VampirTrace? : see here. Martial coded a patch in August 2012. Didier tests it. You can find the results below.
Set-up used :
- Tests done on Curie, WORKDIR disk
- 1M simulation, with restarts, daily outputs, ncc forcing files
- SECHIBA_HIST_LEVEL = 11, STOMATE_HIST_LEVEL = 10, no IPCC output
- Jobs launched on large nodes, because of a potential bug affecting the counters for the thin nodes (TGCC, personal communication)
- Results shown : 8 PROCS, 16 PROCS, in percentage
The aim was to diminished the time for writing the outputs, especially on the last processor.
Optimization of moycum subroutine
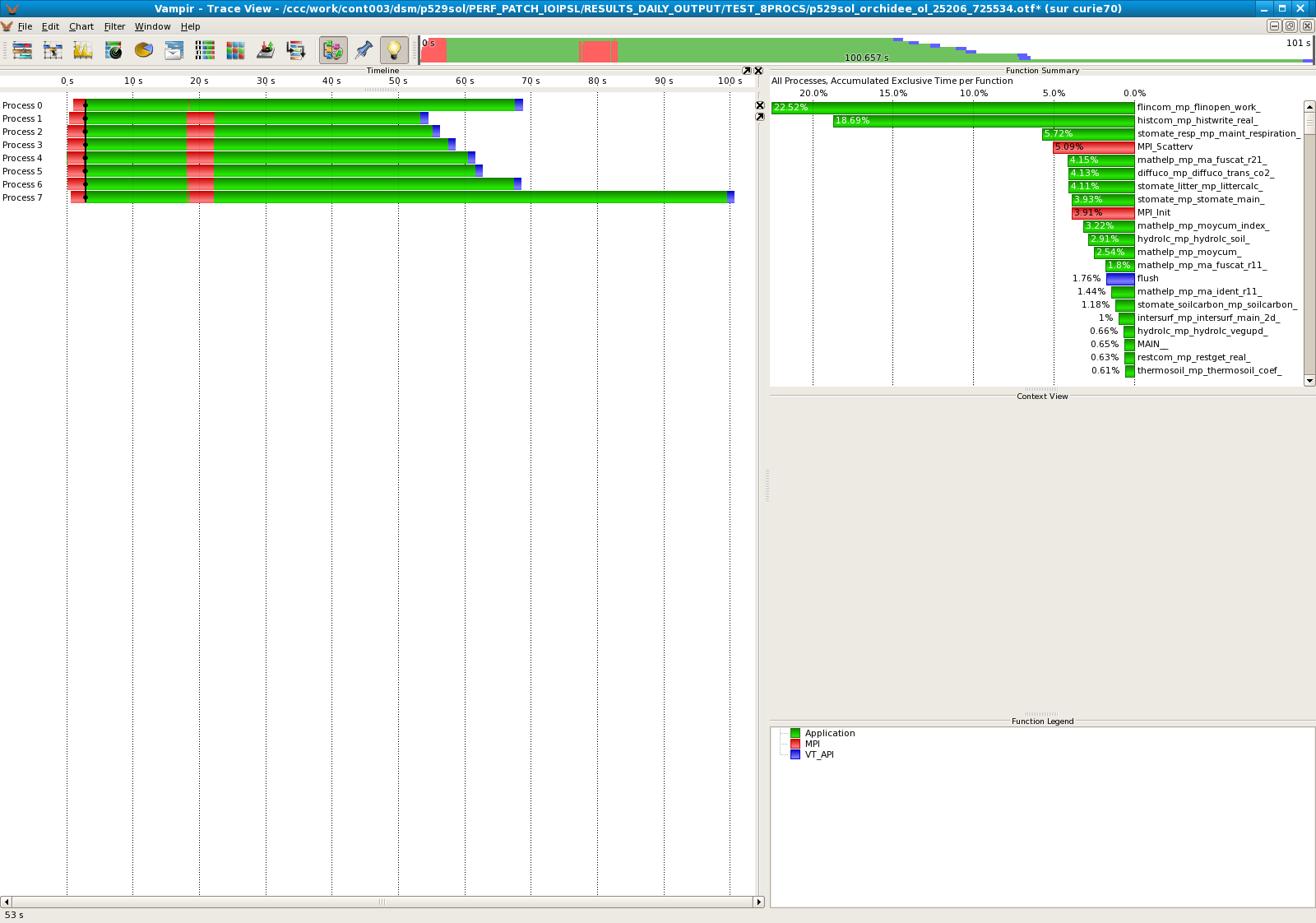
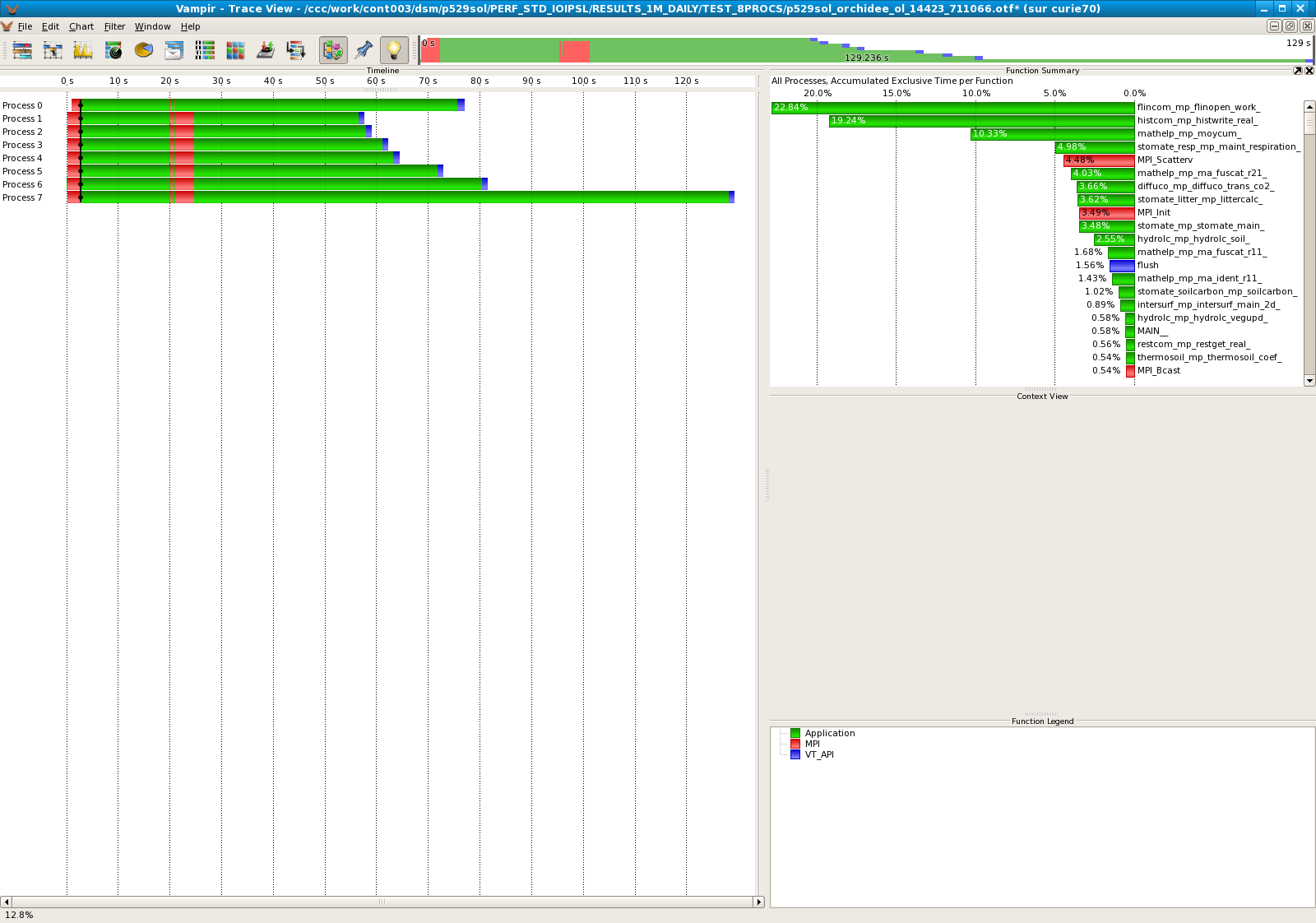
Results for 8 processors
- Standard IOIPSL :

- IOIPSL with patch :

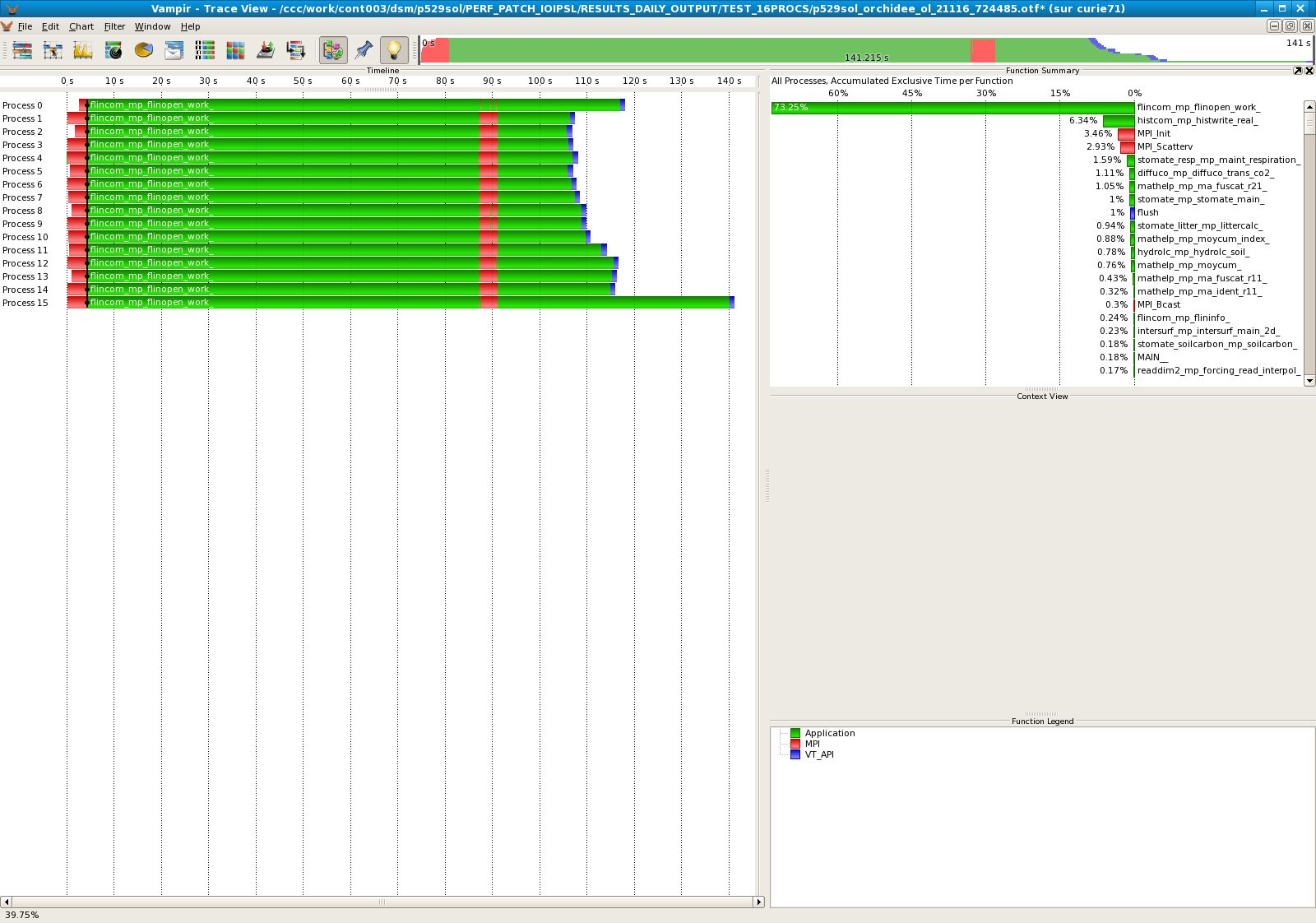
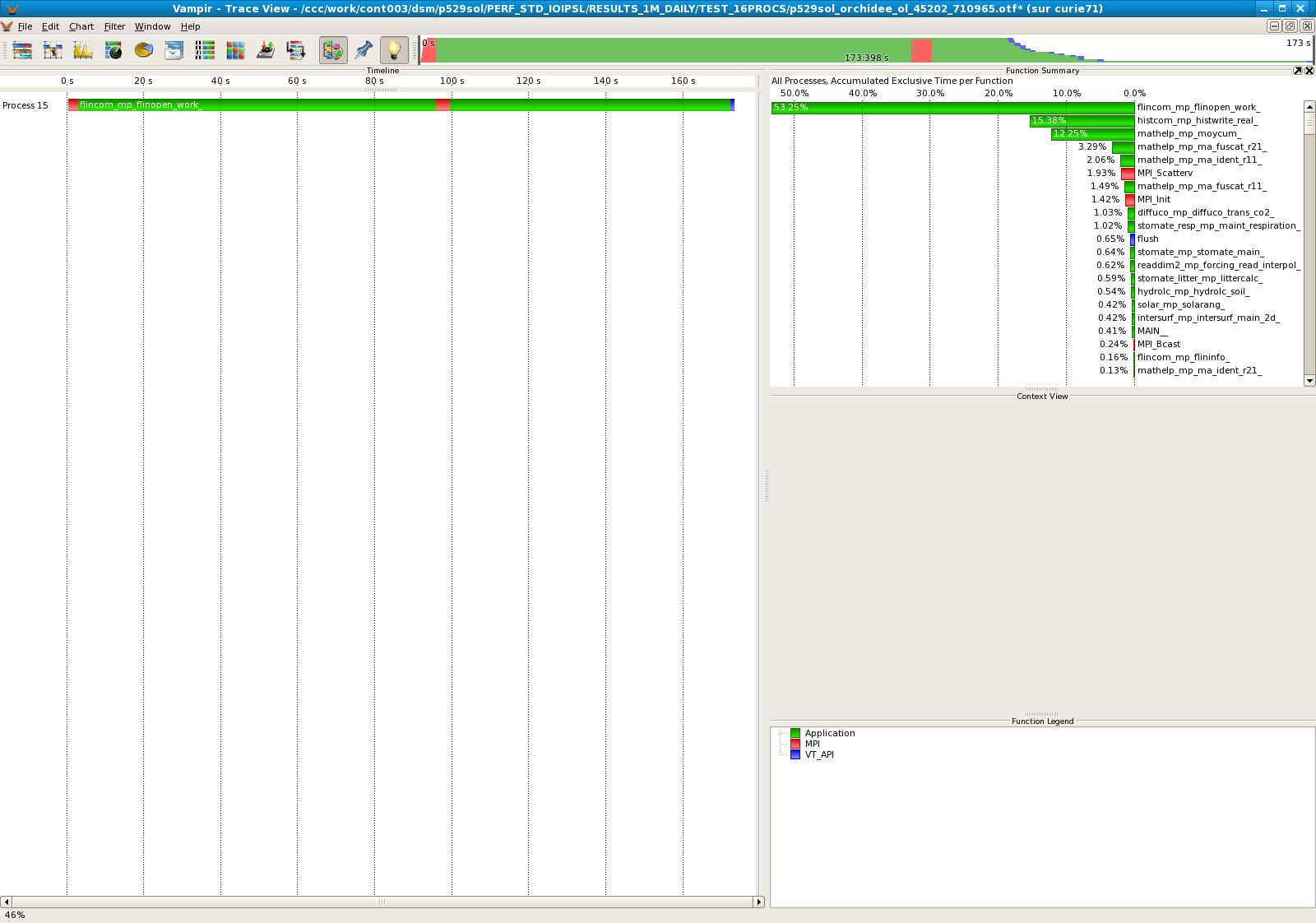
Results for 16 processors
- Standard IOIPSL :

- IOIPSL with patch :

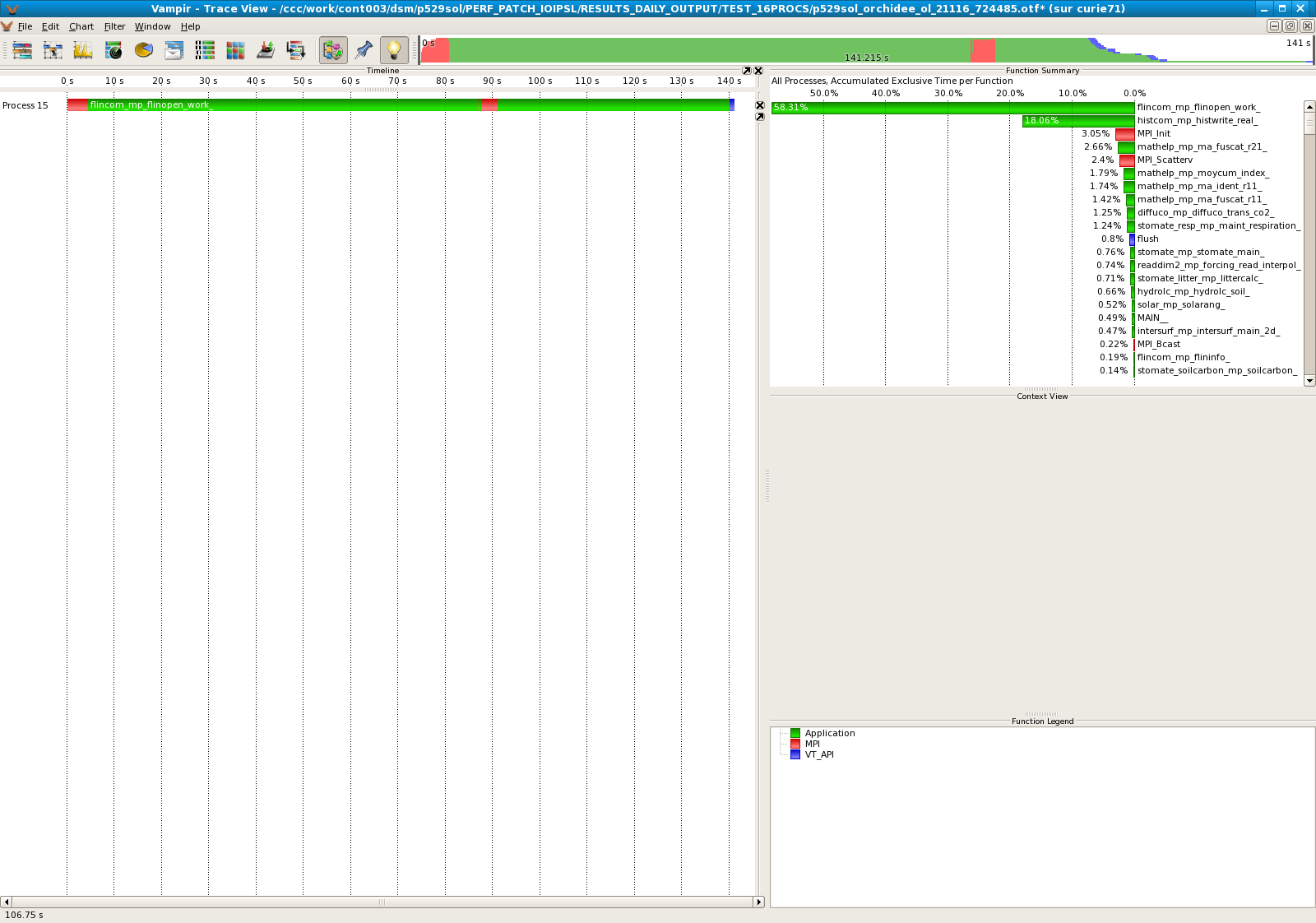
- Standard IOIPSL, processor 16 only :

- Modified IOIPSL, processor 16 only :

| Number of processors | moycum_std (%) | moycum_index (%) |
| 8 | 20,56% | 5,04% |
| 16 | 12,25% | 1,79% |
| 32 | 7,21% | 0,68% |
| 48 | 8,44% | 0,52% |
| 96 | 7,08% | 0,22% |
- Diagnostic : histwrite_real subroutine
| Number of processors | histwrite_real |
| 8 | 26,33% |
| 16 | 15,38% |
| 32 | 13,38% |
| 48 | 12,78% |
| 96 | 9,1% |
- Diagnostic : fliopen_work subroutine
| Number of processors | flinopen_work |
| 1 | 0,53% |
| 8 | 22,84% |
| 16 | 74,27% |
| 32 | 88,23% |
| 48 | 88,57% |
| 96 | 91,68% |
New problem to solve, the routine fliopen_works takes 90% of time computing on 96 processors :

The problem is not specific to the 196 version : it could be noted on the 1952 version with the last tag of IOIPSL :

All processes open the forcing file simultaneously. This problem has to be investigated.
PARTIAL CONCLUSION (September 2012)
- The modified IOIPSL helps to improve the performances of the model. On 16 processors, we divide by 10 the computational time taken by the subroutine moycum. It seems that the last processor always takes much more time that the others. Should we revise the algorithm for the LoadBalance?.dat ?
- An other big problem appears with the subroutine flinopen_work : on 96 processors, this subroutine takes 90% of the time computing! This problem neutralizes the patch.
- Possible explanations : bug in IOIPSL, bug in the parallelization, bad use of Vampir?
- To investigate : why flinopen takes so much time? Test with previous ORCHIDEE tag and IOIPSL tag (DONE, see above). Study the influence of th file LoadBalance?.dat.
INVESTIGATION ON INPUT PROBLEMS (October 2012)
- After some tests, I found the line which causes the problem :
iret = NF90_GET_VAR (fid,vid,vec_tmp,start=(/ 1 /),count=(/ ttm /))
I put some VAMPIR marks before and after the line like this (I replace the original memory allocation for vec_tmp by a local array vec_tmp_ttm) :
VT_USER_START('NF90_GET_VAR')
iret = NF90_GET_VAR (fid,vid,vec_tmp_ttm,start=(/ 1 /),count=(/ ttm /))
VT_USER_END('NF90_GET_VAR')
and I obtain the following figure :

When I replace this netcdf instruction by an array initialization for ncc forcing :
vec_tmp_ttm = (/ (iv, iv = 1,1461) /)
I obtain the following results :

Time computation is divided by 3 !
QUESTIONS :
- Problem from netcdf library ? By default, I was using 3.6.3. Should test another nectdf version. ==> NO
- Problem from disk on Curie ? Try a run on Obelix by using the instruction CALL cpu_time (Vampir cannot be used on Obelix).
ANSWERS FROM YANN (08/10/2012) :
The problem is a hardware problem : the lustre system used by TGCC is configured for "big" files. When some data are read into a netcdf file, 2Mo of memory is used by the system. Moreover, the array vec_tmp contains data which are not contiguous in the netcdf file. Solutions proposed :
- dim2_driver/readdim2: the processus 0 only reads the forcing file.
- flincom : reads only 2 values
- forcing file : use LIMITED instead of LIMITED
PATCH :
- Josefine suggested to modify the call to fliopen :
* comment line 84 : call flinclo * Modify the calling to flinopen line 105 (and allocation of itau) : ttm_part=2 ! Here only read the 2 first values of time axis ALLOCATE(itau(ttm_part)) CALL flinopen & & (filename, .FALSE., iim_full, jjm_full, llm_full, lon_full, lat_full, & & lev_full, ttm_part, itau, date0, dt_force, force_id)
After first tests, the results are OK, we have the same performance when we set 2 in flincom module. See ticket #40.
Patch Evaluation
Test : NCC forcing files (1°)
In order to study both the influence of the IO patches and the Load balance file, I make a survey using the following setup :
- NCC forcing file : 360*180, 15238 land points
- 10 years starting from scratch to study the influence of the Load balance file.
- sechiba_hist_level = 4
- stomate_hist_level = 5
- 125 variables written in the output !
- Monthly outputs
- Tests done on Curie
- REBUILD is done after the run
I calculate the average computation time over the 5 last runs. So we are sure that the load balance file is "stabilized".
| Nb processors | Average time without patches (seconds) | Average time with patches (seconds) | Time gain (ratio) |
| 8 | 920.69 | 790.15 | ~15% |
| 16 | 495.84 | 406.85 | ~18% |
| 32 | 573.00 | 234.4 | ~59% |
| 48 | 510.61 | 202.55 | ~61% |
| 64 | 433.53 | 191.90 | ~55% |
Notice that the patch is significant for a high number of processors (>16). For 32 and 48 processors, the gain is about 60% (it seems that it is the optimal for NCC).
After 48, the gain diminished.
Recommendations for NCC forcing :
- NCC forcing files : 32 processors
To know how the parallelization has been improved, you could read the following report here (in french sorry!). In this report, the optimal number of processors was evaluated to 6 for NCC forcing files!
Test : CRU-NCEP (0.5°)
With Nicolas Viovy, we agree on a common protocol to compare his version and the standard one :
- CRU-NCEP forcing file : 0.5°, ~60000 land points
- 3 years stating from scratch to study the influence of the Load balance file.
- sechiba_hist_level = 1
- stomate_hist_level = 1
- ~20 variables written in the output !
- Monthly outputs
- Tests done on Curie
- REBUILD is done after the run
SECHIBA_hist_level and STOMATE_hist_level are voluntary low, because Nicolas has about 20 variables in his output files.
Results :
- Nicolas version :
| Number processors | Time per processor |
| 32 | ~20 min (evaluation) |
| 64 | 10 min |
| 128 | ~5 min |
- Standard version (trunk, revision 1076) :
| Number processors | Time per processor |
| 16 | 24 min |
| 32 | 16 min |
| 48 | 13 min |
| 64 | 11 min |
| 128 | 9 min 30 |
Conclusion :
- The performance between Nicolas and standard version are similar until 64 processors. After, there are no more improvements in the standard version.
- For CRU-NCEP forcing files, the optimal number of processors is 64. Don't use more : you will use too much time computing.
- With the standard version, you can use the routing. It is not really possible with Nicolas version.
- There are still two problems to solve :
- Change level output for some variables : there are too many variables written by ORCHIDEE. We could set to level 1 all the essential variables necessary to performed a spin-up.
- Why we lose scalability when we use more than 64 processors ?
ACTIONS :
- Redefined output level for ORCHIDEE variables
- Use Vampir to understand the behaviour of ORCHIDEE on a high number of processors.
Attachments (5)
- PATCH_PERF_16PROCS.png (162.2 KB) - added by dsolyga 12 years ago.
- STD_PROC_16.png (114.7 KB) - added by dsolyga 12 years ago.
- PATCH_PROC_16.png (124.3 KB) - added by dsolyga 12 years ago.
- PERF_PATCH_8PROCS.png (123.9 KB) - added by dsolyga 12 years ago.
- PERF_STD_8PROCS.png (123.1 KB) - added by dsolyga 12 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip