| Version 6 (modified by dsolyga, 12 years ago) (diff) |
|---|
Parallelism performances of ORCHIDEE
The performances of ORCHIDEE in parallel are very poor. Martial identified the problem with VampirTrace? : see here. Martial coded a patch in August 2012. Didier tests it. You can find the results below.
Set-up used :
- Tests done on Curie, WORKDIR disk
- 1M simulation, with restarts, daily outputs
- Jobs launched on large nodes, because of a potential bug affecting the counters for the thin nodes (TGCC, personal communication)
- Results shown : 8 PROCS, 16 PROCS, in percentage
The aim was to diminished the time for writing the outputs, especially on the last processor.
Optimization of moycum subroutine
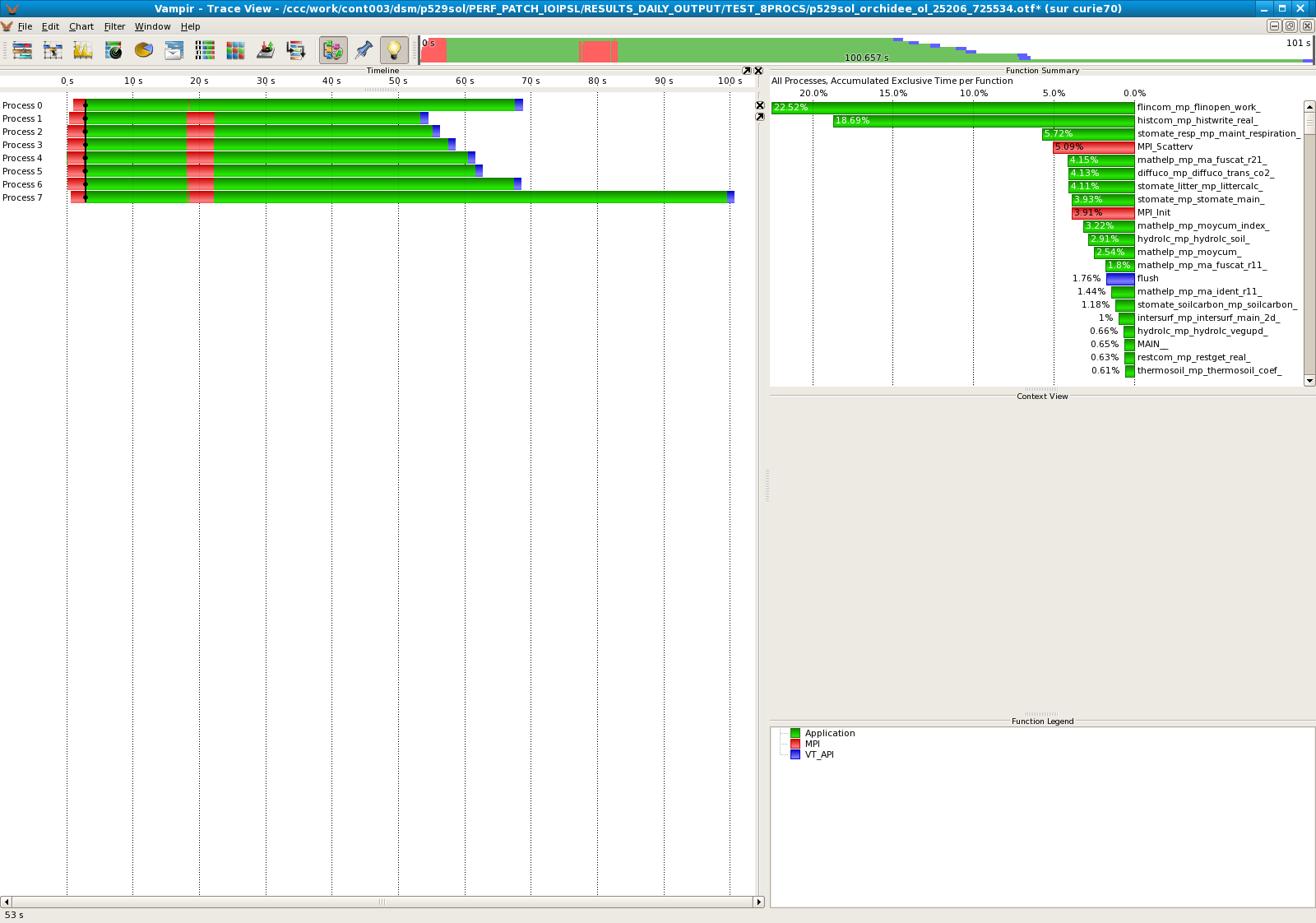
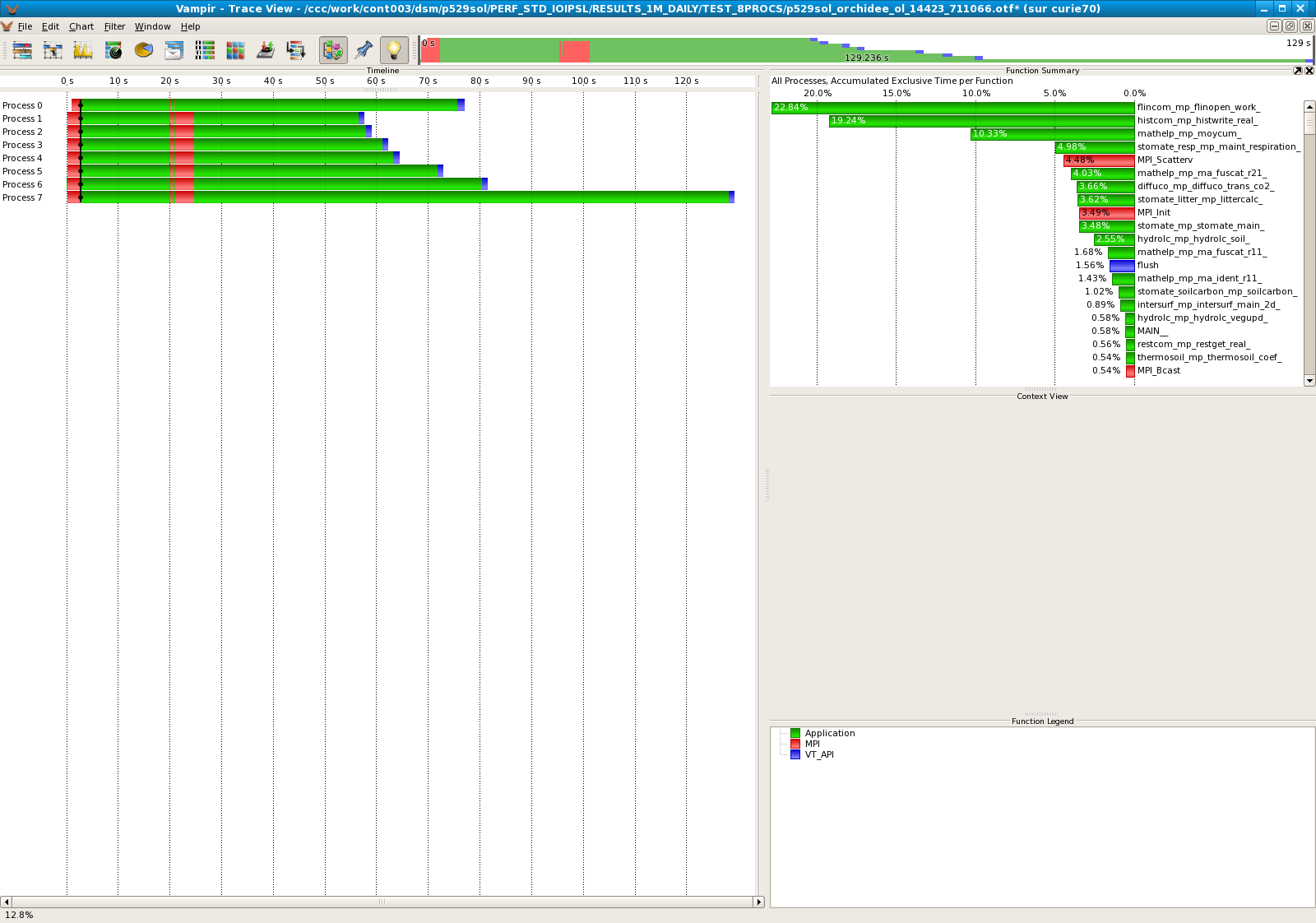
Results for 8 processors
- Standard IOIPSL :

- IOIPSL with patch :

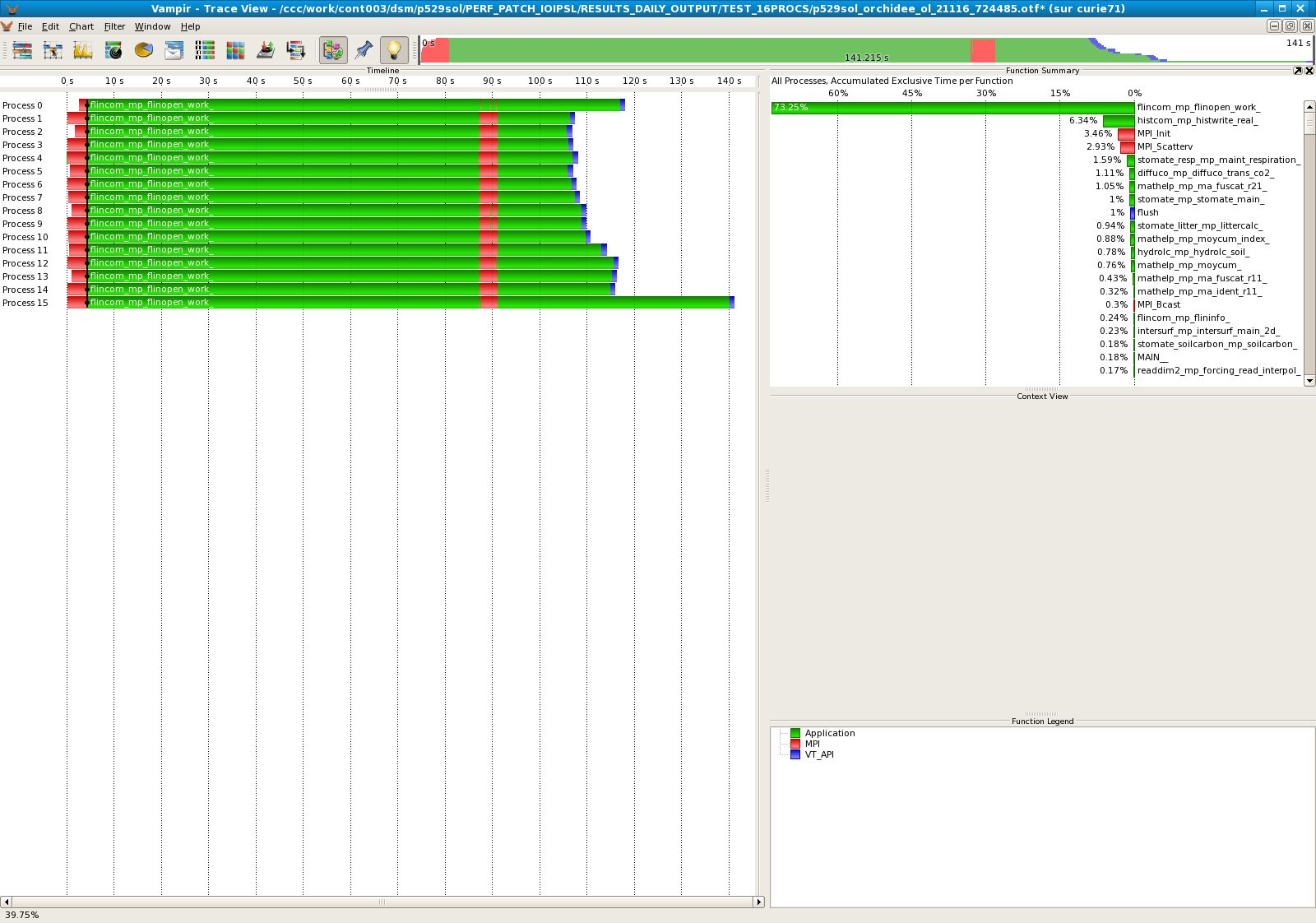
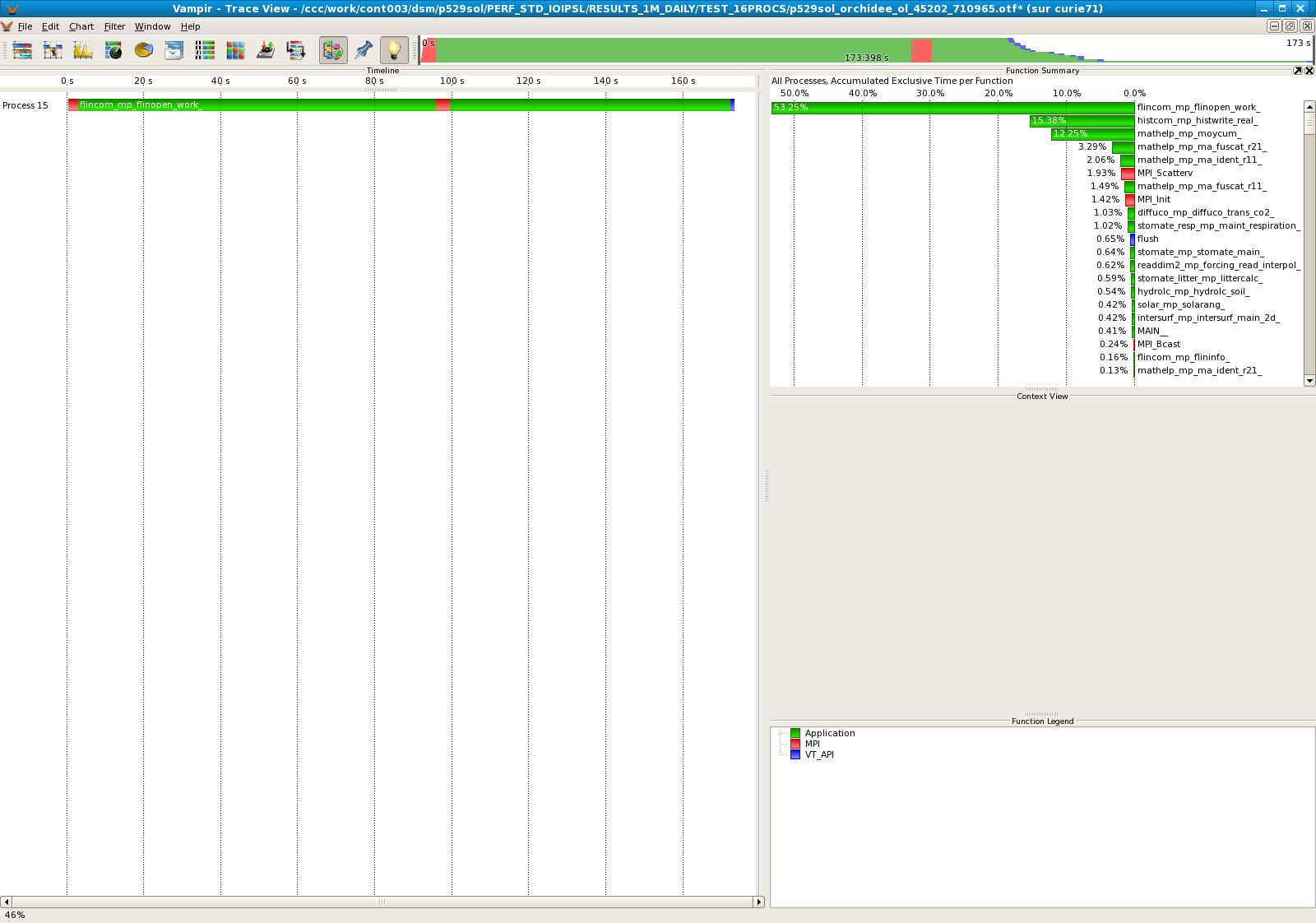
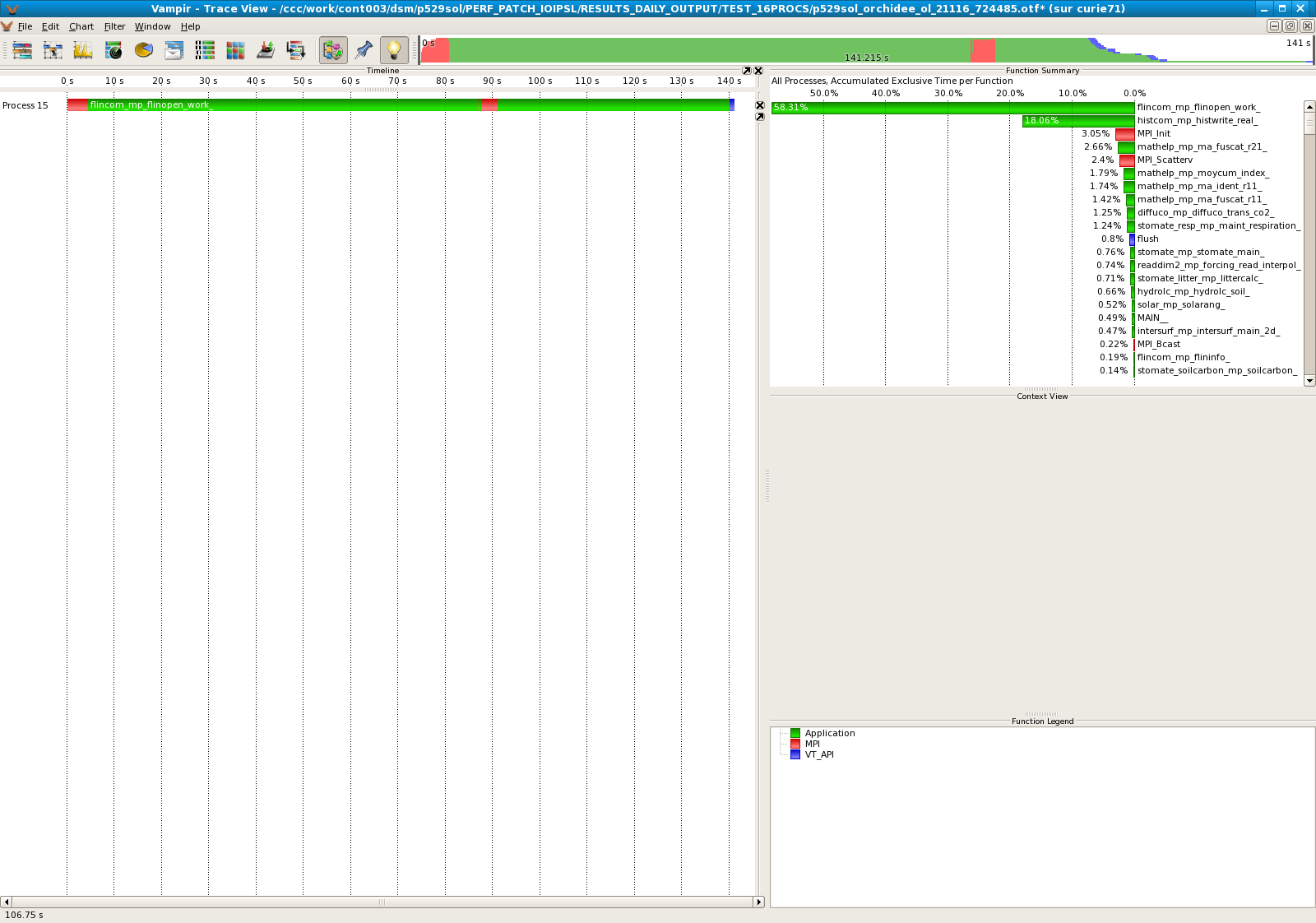
Results for 16 processors
- Standard IOIPSL :

- IOIPSL with patch :

- Standard IOIPSL, processor 16 only :

- Modified IOIPSL, processor 16 only :

| Number of processors | moycum_std (%) | moycum_index (%) |
| 8 | 20,56% | 5,04% |
| 16 | 12,25% | 1,79% |
| 32 | 7,21% | 0,68% |
| 48 | 8,44% | 0,52% |
| 96 | 7,08% | 0,22% |
- Diagnostic : histwrite_real subroutine
| Number of processors | histwrite_real |
| 8 | 26,33% |
| 16 | 15,38% |
| 32 | 13,38% |
| 48 | 12,78% |
| 96 | 9,1% |
- Diagnostic : fliopen_work subroutine
| Number of processors | flinopen_work |
| 1 | 0,53% |
| 8 | 22,84% |
| 16 | 74,27% |
| 32 | 88,23% |
| 48 | 88,57% |
| 96 | 91,68% |
New problem to solve, the routine fliopen_works takes 90% of time computing on 96 processors :

PARTIAL CONCLUSION (September 2012)
- The modified IOIPSL helps to improve the performances of the model. On 16 processors, we divide by 10 the computational time taken by the subroutine moycum. It seems that the last processor always takes much more time that the others. Should we revise the algorithm for the LoadBalance?.dat ?
- An other big problem appears with the subroutine flinopen_work : on 96 processors, this subroutine takes 90% of the time computing! This problem neutralizes the patch.
- Possible explanations : bug in IOIPSL, bug in the parallelization, bad use of Vampir?
- To investigate : why flinopen takes so much time? Test with previous ORCHIDEE tag and IOIPSL tag. Study the influence of th file LoadBalance?.dat.
Attachments (5)
- PATCH_PERF_16PROCS.png (162.2 KB) - added by dsolyga 12 years ago.
- STD_PROC_16.png (114.7 KB) - added by dsolyga 12 years ago.
- PATCH_PROC_16.png (124.3 KB) - added by dsolyga 12 years ago.
- PERF_PATCH_8PROCS.png (123.9 KB) - added by dsolyga 12 years ago.
- PERF_STD_8PROCS.png (123.1 KB) - added by dsolyga 12 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip